Towards AI Generated Games in the Learning space: Uniplay’s Vision
Alejo Pérez Gómez just published a deep dive into AI, game-based learning and what continuous learning could look like in an AI-driven world.
Tech

Alejo Pérez Gómez
May 26, 2026
Tech
A Uniplay learning course starts as raw material: PDFs, URLs, text, transcripts. Our AI engine turns that into Discovery content (the curated learning material for a level), which then drives game generation, car races, adventures, and voice-driven scenario roleplays. Today the types of games are fixed templates. What we want tomorrow, though, is that the games themselves are generated.
The output we care about is not “a game” in the abstract sense. It’s a playable, on-brand experience that fits a specific learner, a specific topic, and a specific moment in their journey. That’s a much harder target than “an LLM that can write game code”, and it’s the one we’re optimising for.

The first job is not generation, it's curation. Our agentic content pipeline reads the source material, decides what's worth teaching at each level, and synthesises Discovery content tailored to the course context. This is where the pedagogy lives. If this layer is wrong, no amount of clever generation downstream can rescue it.
This part is heavily agentic but human-supervised today. The admin reviews, edits, and ultimately publishes. We treat that as a feature, not a limitation.
On top of Discovery, we run structured generation for game content. Scenario characters, adventure branches, and knowledge challenges are produced as reliable data structures conforming to strict schemas. Character profiles, conversation states with transitions, success/failure phrases, etc.
We use frontier code agents (Claude, Gemini-class CLIs and similar) where they make sense, and we deliberately keep the orchestration provider-agnostic with fallback chains. If one provider degrades or outages, the pipeline keeps working with a different model. Lock-in would be costly in a market where every quarter brings a better model.
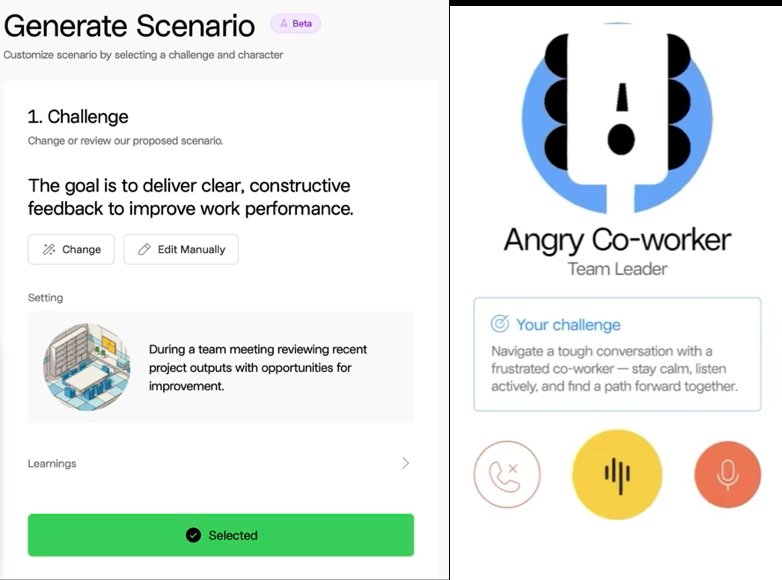
This is the piece we're proudest of today, and when I talk to some people at networking events, sometimes underestimate. The admin, or increasingly the learner themselves, opens a clean UI panel and creates characters and situations anchored to the Discovery content. "Roleplay an HR conversation about hiring rules." "Roleplay a procurement officer testing whether you'll accept a bribe."
The learner then practices live, by voice, with a real-time character agent. Not multiple-choice. Not text. Voice. Once the practice ends, they talk to a coach (a separate agent that reviews the session and gives concrete, situated feedback on what to do better next time).
The pedagogical bet is that retention happens when learners do the thing, then immediately reflect on it with a guide. That's expensive to staff with humans at scale, and it's exactly what AI is good at, provided the harness around it (rubric, evaluation, content grounding) is built carefully.
This is one of the hardest problems with AI-generated content — it isn't generating it, it's keeping the bad outputs out. For knowledge-based games, every generated question passes through an LLM-as-judge loop before it reaches a learner. Questions that fail are regenerated with both positive and negative examples as guidance; if we still fall short of the minimum count, a backfill step picks the best of the rejects so downstream contracts are never silently violated.

The rubrics the judge uses aren't generic. They're written by domain experts and encode learning-science principles specific to each content type: what counts as a trivial distractor, when a question telegraphs its own answer, how tone should shift between compliance training and skills coaching. The agent loop owns correctness; the domain guidelines decide what correctness means.
If code is cheap and generation is automatable, where does the team spend its time? Mostly on the things that aren't the game itself. The harness inputs: schemas, rubric prompts, anti-patterns, and spec files the agents consume.
The UX guidelines and design tokens the generator must respect, so a generated game doesn't look or sound off-brand. The personalisation profile kept for each learner, which conditions both the Discovery content and the game mechanics.
That's the leverage. The agents do the typing; the UX team and the learning scientists decide what good looks like, and the harness enforces it.
We think about AI-generated games as a four-stage maturity model. These are vision levels, not to be confused with the per-course level units the admin app already uses.

Level 1 is where we are today. Examples already in production: an anti-bribery roleplay where the learner has to refuse without being preachy; an HR consultant scenario where the learner applies hiring rules under pressure; and the AI voice practice and coaching module described above. The hard part isn't getting an MVP working, it's stopping the pipeline from producing off-tone characters and throw-off questions at scale.
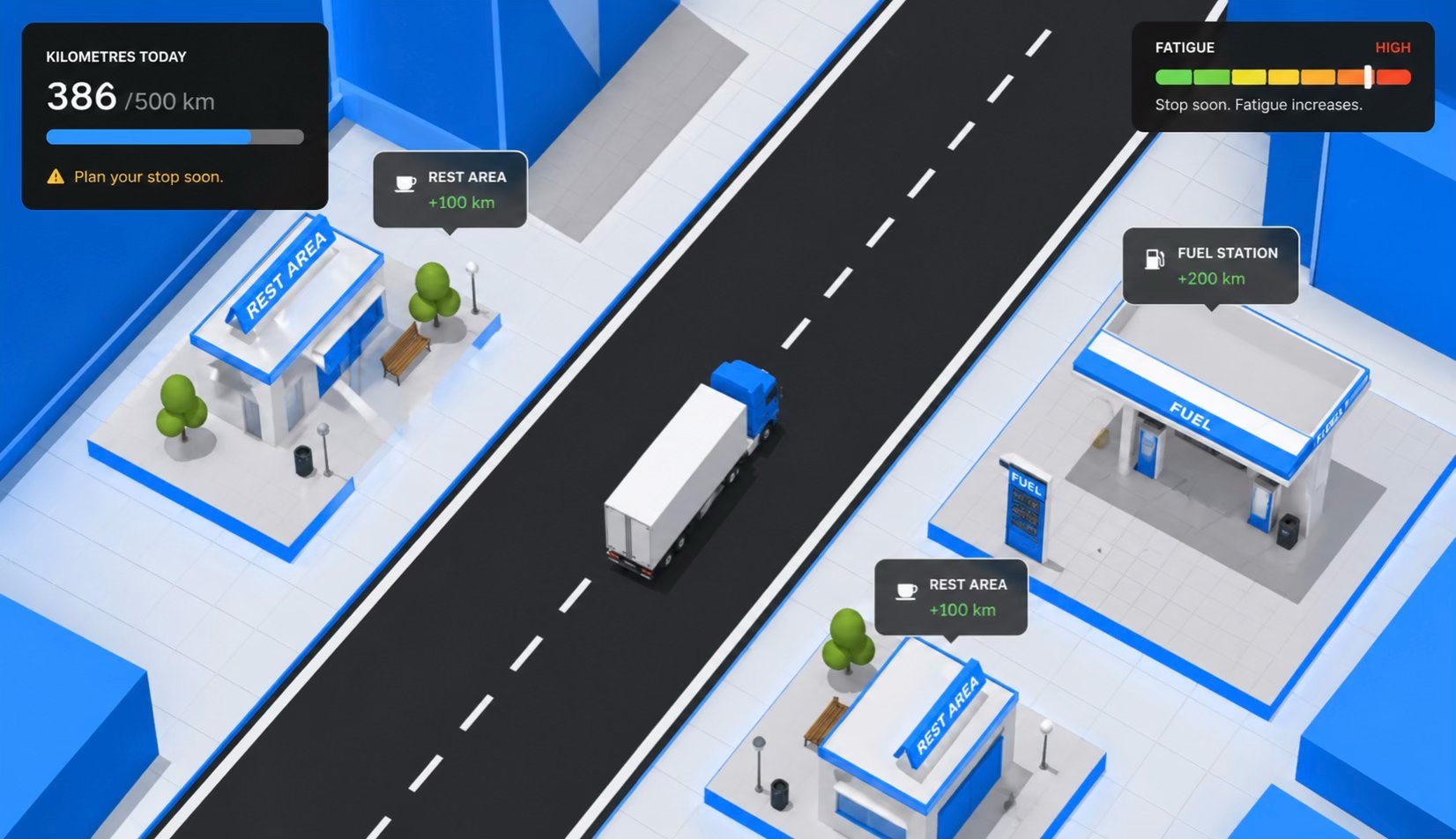
Level 2 is what we’re experimenting with now. Example: a truck-driver fatigue simulation where the learner watches a kilometre counter and has to stop at the right moment, with the safety rule baked implicitly into the mechanic itself rather than asked as a question. The challenge is reliability — a dynamic mechanic that misbehaves once is worse than a boring one that always works.
Level 3. Level 3 is what we're currently exploring. Immersion via world models (Genie 3, Hunyuan World, and their successors). Avatar-led experiences inside a generated world, with game mechanics layered on top. The compute is heavy and the ground is new, but we're already looking at what it takes to build something custom and start small: an avatar, a world, a few stations.

A parallel challenge runs through all four levels: platform plumbing. Uniplay centralises session management, level administration, XP, and the in-game economy. Generated games have to plug into this cleanly. Experimental prototypes are intentionally session-less for now. They indeed prove the mechanic, not the integration.
We are deliberately not locked into one provider. The scenario generator falls back across providers automatically. The judge model is configurable. Prompts live in Langfuse so we can roll versions without redeploying. When a new model is meaningfully better, we want to be able to switch in hours, not quarters.
We don’t have a fully automated game factory. We have a strong Level 1 in production, promising Level 2 prototypes, and a clear vision towards Level 3. Human-in-the-loop is still a core part of the system, and that’s the right place to be in 2026. That is not because the models can’t do more, but because trust is earned one good generation at a time.
We’re publishing this because we want feedback. If you’re a learning designer, a builder, or a partner: what would you want us to automate first? Where does “good enough” actually start? Which learning domains do you think are hardest to generate well?





